
Dataset Creation and Labeling Process for YOLO: A Step-by-Step Guide
This article provides a detailed explanation of the dataset creation and labeling process required for object detection using the YOLO algorithm. It covers the importance of collecting quality data, the use of labeling tools, the structure of the YOLO format, dataset splitting (train/valid/test), and methods to prevent overfitting with examples.
DATASET CREATION AND DATA LABELING
Data Collection
The most important part of building a good model is having a high-quality and diverse dataset. First, the dataset should contain images taken from environments and scenarios similar to the ones where the model will be deployed. For example, if the model will work outdoors, the dataset should include conditions such as foggy, overcast, snowy, and rainy weather. This significantly increases the model's performance.

Data Labeling
In order to train our model, we need to make the data meaningful for the algorithm. The label format varies depending on the algorithm to be used. For YOLO, there are several tools available for labeling, such as LabelImg, Labelbox, and the online platform Roboflow. Below is an example of a labeled image using LabelImg and the content of the corresponding output .txt file.
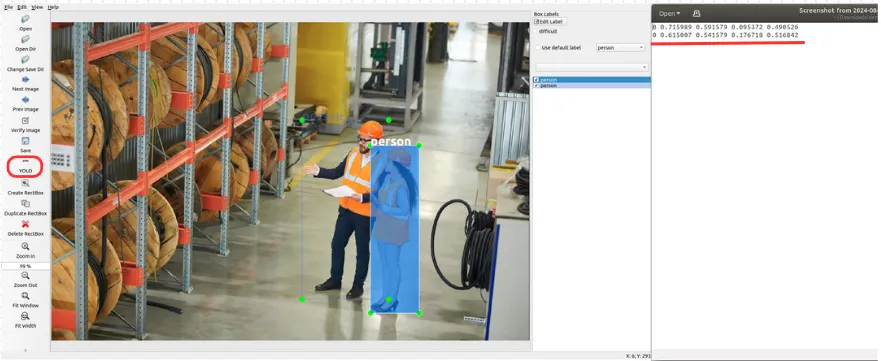
For the above example using LabelImg, the YOLO format was selected and the annotation was saved accordingly. The YOLO label format output consists of the following values in order: Class ID, x_center, y_center, width, and height.
- The Class ID refers to the class of the object, in this case, class 0 corresponds to "person".
x_centeris the normalized x-coordinate of the bounding box center.y_centeris the normalized y-coordinate of the bounding box center.width_normis the normalized width of the bounding box.height_normis the normalized height of the bounding box.
Except for the Class ID, all values must be between 0 and 1.
How can we determine the position of the labeled object on the image using YOLO-formatted data?
Using the image and .txt file shown above, we can calculate the actual pixel positions as follows, assuming the image resolution is 640 × 480:
- To find the X position:
- To find the Y position:
- To find the width:
- To find the height:
After completing the labeling process, the dataset must be prepared in a format suitable for training. It should be divided into training (train), validation (valid), and test subsets. The commonly recommended split is 85% for training, 10% for validation, and 5% for testing.
If we have videos for later testing or the capability to perform real-time tests, we may skip creating a test set and instead allocate all the data for training. Another important aspect is to distribute the dataset evenly across subsets. This can be done using online tools like Roboflow or with a simple local script. The key is to use shuffling to ensure a homogeneous distribution.
Training Set: This portion of the dataset is used to train the model. The model learns from this data and updates its weights.
Validation Set: Used during training to tune model parameters and prevent overfitting. It helps ensure that the model performs well not just on the training set but on unseen data too. Early stopping techniques can be applied based on performance on the validation set to mitigate overfitting.
Overfitting: This occurs when the algorithm performs exceptionally well on the training data by essentially memorizing it, but fails to generalize to new, real-time inputs. Although the training metrics may look perfect, the model may not actually perform well during inference.
Solutions for overfitting:
- Increasing the diversity of the dataset is the most effective way to combat overfitting. A narrow dataset encourages overfitting, while broader scenarios and conditions help the model generalize.
- Apply early stopping when the performance gap between training and test data reaches a certain threshold.
- Some algorithms like YOLO attempt to apply early stopping automatically during training.
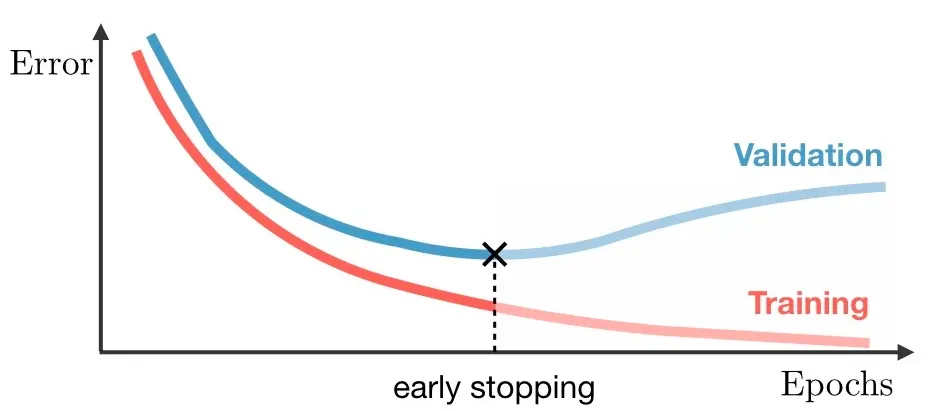
Test Set: This dataset is used after training to evaluate how the model performs on new, unseen data. The test phase is important to determine the model’s effectiveness in real-world conditions and to identify areas for improvement.
#Data #Dataset #Train #Valid #Test #Overfitting #EarlyStopping #Model #YoloTraining #LabelImg #Roboflow #Yolov5