
Computer Vision and Object Detection: Fast and Accurate Solutions with the YOLO Algorithm
This article thoroughly explores the concept of computer vision, the object detection process, and commonly used algorithms. It provides a step-by-step explanation of how the YOLO algorithm works, how bounding boxes are generated, and how confidence scores are calculated, along with comparisons to other algorithms.
What is Computer Vision?
With the rapid advancement of technology today, access to cameras and powerful computers has become easier. As a result, capturing images and videos has become a routine activity. The need to analyze these easily accessible images and make the analyses meaningful has emerged. In image processing, features such as object detection allow the identification of objects, items, or body parts in images; image segmentation breaks down large images into smaller, more meaningful parts; and object tracking enables the monitoring of the movement of detected objects.
Common fields where computer vision is frequently used include: medical imaging (MRI, X-ray) and disease diagnosis in healthcare; object recognition and road sign detection in autonomous vehicles in the automotive sector; customer density, movement, and inventory management in retail; facial recognition and unauthorized entry detection in security; quality control and robotic process automation on production lines in industry; and in occupational health and safety, applications based on object detection such as monitoring personal protective equipment and restricted area violations.

What is Object Detection?
Object detection is the process of identifying and classifying objects in an image or video frame. This process not only informs us of the presence of an object in the image but also helps determine its position. Object detection is one of the most fundamental areas of computer vision and is typically the first step in computer vision projects. Object detection algorithms are generally implemented using deep learning and neural networks.
The basic steps include:
- Data collection and preparation: Gathering a large number of images containing the target objects and labeling them in a format suitable for training.
- Model training: Training a deep learning model with the prepared dataset using the appropriate method.
- Model inference: Testing the trained model on images outside the training dataset that contain the target objects and evaluating the results. If deficiencies are identified, new data should be added to the training set.
Popular object detection algorithms include:
-
Faster R-CNN (Region-based Convolutional Neural Networks): Uses region proposal networks for more accurate object detection. While it offers high accuracy, it's slower and therefore not ideal for real-time applications.
-
SSD (Single Shot Multibox Detector): Uses multiple bounding boxes at different scales for detection. It’s close to YOLO in speed but performs better at varying scales. However, it requires more memory, making it less suitable for smaller devices.
-
RetinaNet: Uses the focal loss function to handle the imbalance between positive and negative examples. This allows for better performance on large images with few objects.
-
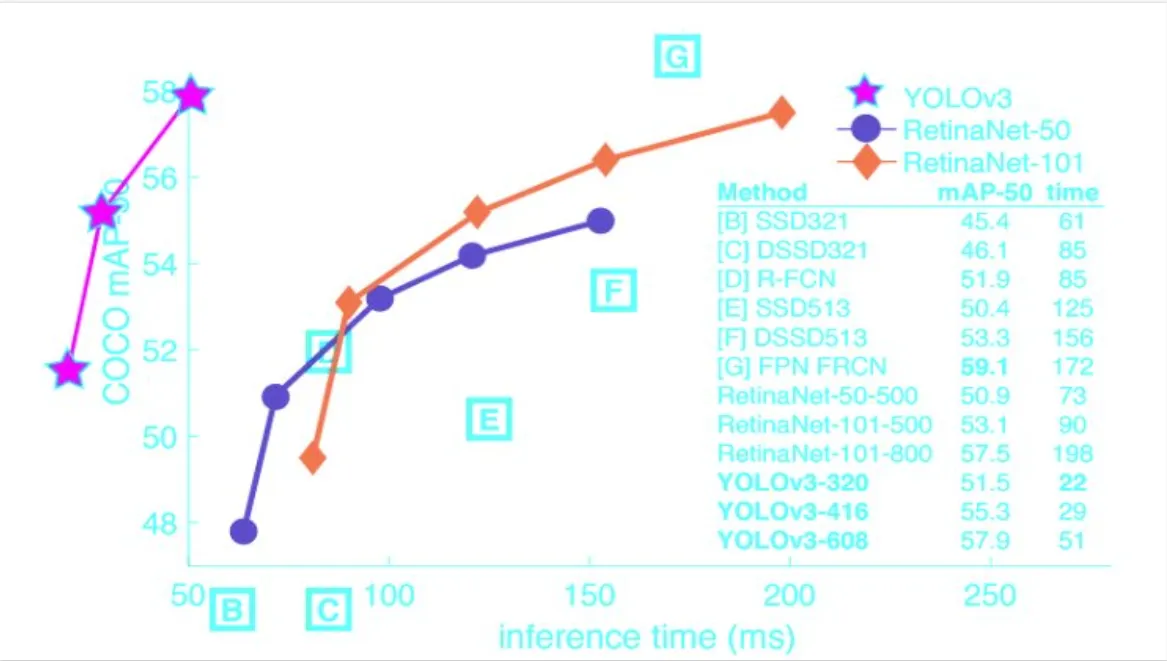
YOLO (You Only Look Once): A deep learning algorithm used for object detection and classification in images. It is preferred for real-time object tracking applications due to its speed and efficiency compared to other algorithms.
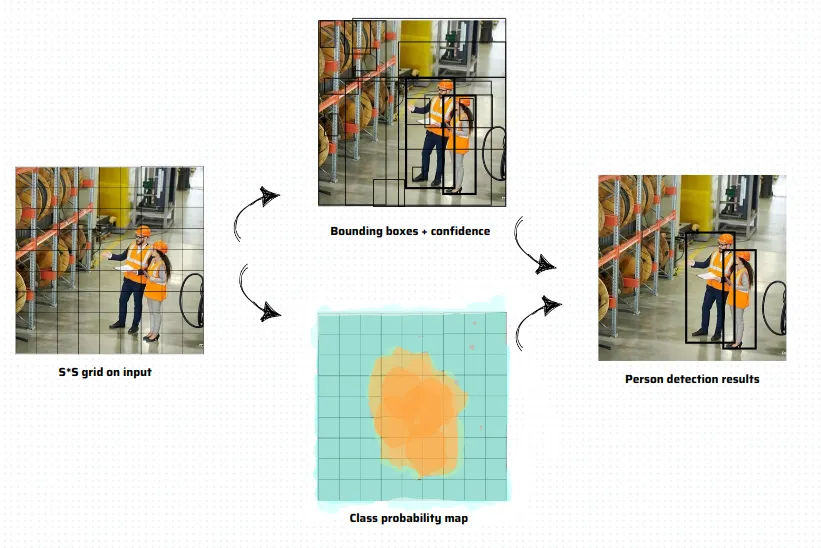
YOLO ALGORITHM
The YOLO algorithm works by passing an image through a neural network once to predict the classes and positions of objects. To perform classification or localization, it first divides the image into grids. Each grid performs object presence checks using deep learning. If the object is assumed to be present, it checks whether the object's center is within the grid. Then, it calculates bounding box parameters such as width, height, and confidence score. After passing through the neural network, the output is a vector.

The variables in this vector are interpreted as follows:
- Pc: Probability of class presence. Expressed as 1 or 0, where 1 means an object is present and 0 means absent. In the image shown, Pc is 1 due to the presence of a "person" class.
- Bx, By: X and Y coordinates of the bounding box center.
- Bw, Bh: Width and height of the bounding box.
- C1, C2: Class probabilities. In this example, there are two classes—"forklift" and "person". C1 is 0 because there's no forklift, and C2 is 1 because there's a person.
If no object is present in the image, Pc will be 0 and the other values won’t be generated.
Confidence Score: Indicates the confidence level that a detected object is indeed what the model predicts.
The formula is:
- Pr(obj): Probability that an object is present in the grid.
- IoU: Intersection over Union of the actual and predicted bounding boxes.
Sometimes multiple grids may assume that the object is within their bounds, resulting in many overlapping bounding boxes. To eliminate these redundant boxes, the Non-Maximum Suppression algorithm is used based on the confidence scores.
#ComputerVision #ObjectDetection #Yolo #Non-MaximumSupression #FasterR-CNN #RetinaNet #OccupationalSafety #OHS #QualityControl #ObjectDetection #ComputerVision