
YOLO İçin Dataset Oluşturma ve Etiketleme Süreci: Adım Adım Rehber
Bu yazıda YOLO algoritmasıyla nesne tespiti için gerekli olan veri seti oluşturma ve etiketleme süreci detaylıca ele alınmaktadır. Kaliteli veri toplamanın önemi, etiketleme araçlarının kullanımı, YOLO formatının yapısı, veri ayrımı (train/valid/test) ve overfitting ile mücadele yöntemleri örneklerle açıklanmıştır.
DATASET OLUŞTURMA VE DATA ETİKETLEME
Data Toplama
İyi bir model ortaya çıkarmanın en önemli kısmı kaliteli ve çeşitli bir datasete sahip olmaktır. Modelin kullanılacağı ortama benzer koşullarda ve yaşanabilecek tüm senaryoları içeren görüntülerin dataset içinde bulunması, başarımı ciddi şekilde artırır. Örneğin, dış ortamda çalışacak bir model için hava koşulları da göz önünde bulundurulmalı; sisli, kapalı, karlı ve yağmurlu hava gibi durumlar dataset içerisinde yer almalıdır.

Data Etiketleme
Veriler, eğitim sürecinde algoritma tarafından anlamlandırılabilmesi için etiketlenmelidir. Kullanılan algoritmaya göre etiket formatı değişmektedir. YOLO için etiketleme yapılabilecek birçok araç vardır: LabelImg, Labelbox, Roboflow gibi çevrim içi platformlar. Aşağıda LabelImg ile yapılan bir etiketleme örneği ve çıktı olarak kaydedilen bir .txt dosyasının içeriği gösterilmektedir.
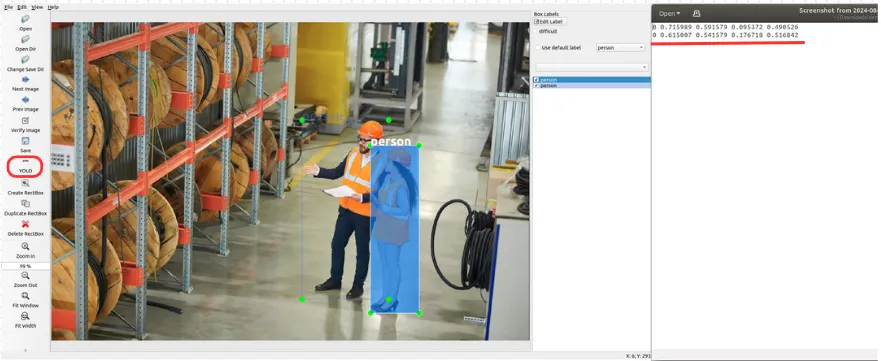
Bu örnekte YOLO formatı seçilmiş ve etiketleme bu formata uygun şekilde yapılmıştır. YOLO etiket formatı şu sırayla değer içerir: Sınıf ID’si, x_center, y_center, width, height.
- Sınıf ID’si, ilgili nesneye karşılık gelir. Örneğin
0değeri “person” sınıfını temsil eder. x_center: Bounding box’ın merkezinin x eksenindeki normalize değeriy_center: Bounding box’ın merkezinin y eksenindeki normalize değeriwidth_norm: Bounding box’ın normalize genişliğiheight_norm: Bounding box’ın normalize yüksekliği
Sınıf ID’si dışındaki tüm değerler 0 ile 1 arasında olmalıdır.
YOLO formatındaki etiket verileriyle görseldeki nesnenin konumu nasıl bulunur?
Üstteki görsel ve .txt dosyasını baz alarak, çözünürlüğü 640 × 480 olan bir resim için şu hesaplamalar yapılabilir:
- X konumu:
- Y konumu:
- Genişlik:
- Yükseklik:
Etiketleme işlemi tamamlandıktan sonra dataset, eğitim formatına uygun şekilde hazırlanmalıdır. Dataset; eğitim (train), doğrulama (valid) ve test olarak bölünmelidir. Yaygın kullanılan oranlar: %85 train, %10 valid, %5 test.
Eğer sonradan test yapabileceğiniz videolar veya canlı test alma imkanınız varsa test setine gerek olmayabilir; bu durumda tüm veriler eğitim için kullanılabilir. Ayrıca dataset’in alt kümelere homojen şekilde dağılması da önemlidir. Bunun için Roboflow gibi çevrim içi araçlar kullanılabilir ya da lokal bir script ile shuffle işlemi gerçekleştirilerek dağılım sağlanabilir.
Train Seti: Modelin öğrenme sürecinde kullanılacak ana veri kümesidir. Model bu verilerle eğitilir ve ağırlıkları günceller.
Validation Seti: Eğitim sırasında modelin performansını izlemek ve overfitting’i engellemek amacıyla kullanılır. Modelin sadece eğitim verisine değil, genel veri kümesine de iyi genelleme yapabilmesi için gereklidir. Validation performansına göre erken durdurma (early stopping) uygulanabilir.
Overfitting: Modelin eğitim verisini ezberleyerek sadece bu veri üzerinde yüksek performans göstermesi, ancak gerçek zamanlı testlerde başarısız olması durumudur.
Overfitting’i azaltmak için:
- Dataset’i çeşitlendirmek en etkili çözümdür. Tek tip veri overfitting’i artırır; farklı senaryo ve ortamlardan veri toplamak gerekir.
- Eğitim ve test hataları arasındaki fark belirli bir eşiğe ulaştığında eğitimi durdurmak (early stopping).
- YOLO gibi bazı algoritmalar eğitim sırasında bunu otomatik olarak yapar.
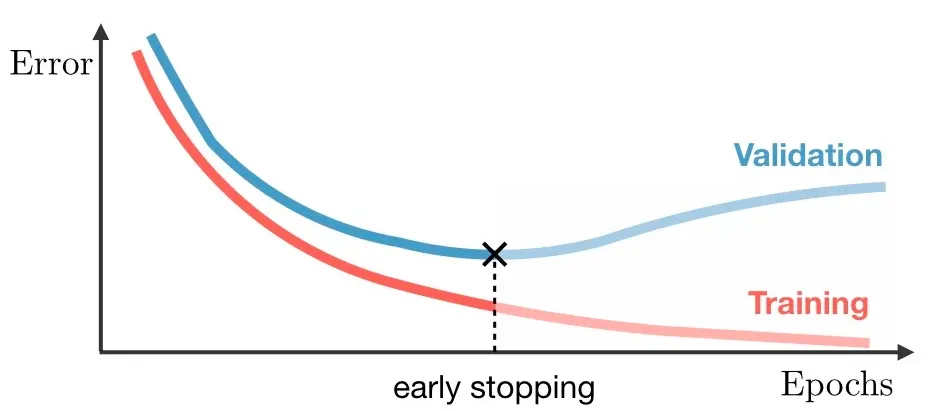
Test Seti: Eğitim tamamlandıktan sonra modelin daha önce görmediği veriler üzerinde nasıl çalıştığını değerlendirmek için kullanılır. Test süreci, modelin gerçek ortamlarda ne kadar başarılı olduğunu görmek ve eksik yönlerini belirlemek açısından kritiktir.
#Data #Veriseti #Train #Valid #Test #Overfitting #EarlyStopping #Model #YoloEğitim #LabelImg #Roboflow #Yolov5